Sql Server Integration Services (SSIS) es una excelente herramienta para la carga, procesamiento y traslado de información entre diferente fuente de datos.
En esta oportunidad escribo un pequeño tutorial de como trabajar formatos de fecha y caracteres especiales como la ñ, o vocales tildadas (á,é,í,ú,ó). Espero que les sea útil como guía.
Primero vamos a detallar la versión de nuestra base de datos:
- Sql Server 2008 R2
- Configuración de Intercalación(Collation): Modern_Spanish_CI_AS
- En la base de datos "Demos", hemos creado la tabla "DummyCargaSSIS", con 6 campos. El campo "ID" es de tipo Int Identity(1,1). La carga de información lo vamos hacer en los otros 5 campos.
Definición del archivo de texto:
- En el archivo de texto "DatosDummy.txt" tenemos 5 columnas separados por el caracter pipe (|).
- Columnas: Código, fecha creación, Nombre, fecha activo y fecha baja
Como pueden observar no todas las filas tienen información en la columna "fecha baja", ademas en la columna "nombre" vienen nombres con caracteres especiales (ñ,á,é,í,ú,ó).
SSIS: Cargar de archivo de texto y subirlo
Tenemos el los datos en el archivo "DatosDummy.txt", nuestro SSIS debe ser capaz de leer los datos e insertarlos en la tabla "DummyCargaSSIS" de nuestra base de datos "Demos". Al SSIS debemos agregar los siguientes componentes tal como lo describe la imagen mas abajo:
- Agregar un "Flat File Connection" y poner por nombre "FFCM_ArchivoDummy": Este se conecta al archivo "DatosDummy.txt"
- Agregar un "Oled DB Connection" y poner por nombre "BDDemos": Se conecta a la base de datos "Demos".
- Agregar un "Data Flow Task"
El siguiente paso es configurar el "Data Flow Task":
- Agregar un "Flat File Source", el cual debe conectarse con el "FFCM_ArchivoDummy"
- Agregar el componente "Derived Column": Importante porque nos va ayudar a ejecutar las conversiones que necesitemos.
Vamos a explicar exactamente un poco que vamos hacer, comencemos.
Flat File Connection Manager
Debemos agregar un "Flat File Connection Manager". En este componente vamos a configurar la ubicación del archivo y "Code Page" a "65001 (UTF-8)". Con esto nos garantizamos que pueda reconocer los caracteres especiales.
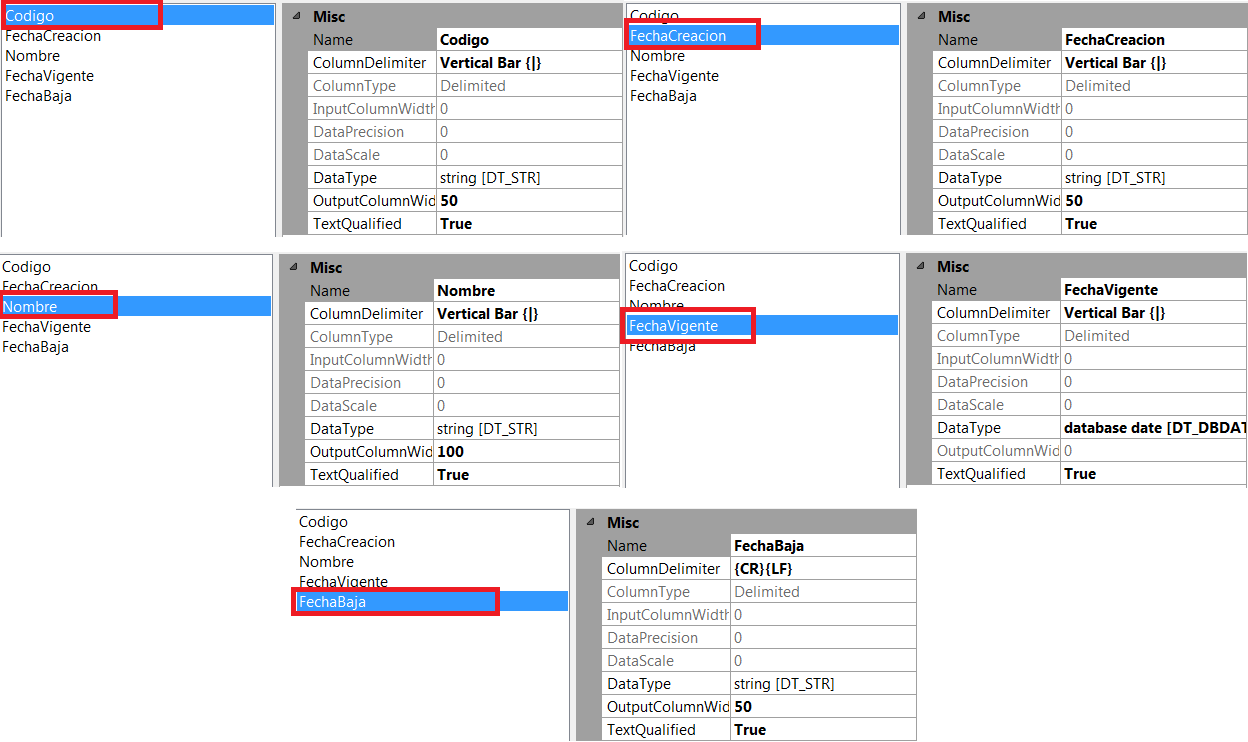
Configuración Columnas "Advanced"
Ahora, vamos a revisar como están configurados cada uno de los campos, para eso vamos a la opción "Advanced".
- Codigo: Tipo String, longitud 50
- FechaCreacion: Tipo String, longitud 50
- Nombre: Tipo String, longitud 100
- FechaVigente: Tipo DT_DBDATE (database date)
- FechaBaja: Tipo String, longitud 50
Si son observadores, podemos observar que el campo "FechaVigente", no viene como tipo String, sino que viene como DT_DBDATE....
En Sql Server, el formato de la fecha (casi siempre), es YYYY-MM-DD. En el archivo de texto para este campo vienen con este formato, entonces con solo indicarle que sea DT_DBDATE, el proceso lo castea y sin ningún problema lo sube a la base de datos. Este es un ejemplo de conversión implícito.
Image de cada campo
Si se observa en el Preview podemos validar que los datos se visualiza tal como se visualiza el archivo de texto. Vamos por buen camino.
Data Flow Task
En esta tarea procedemos a colocar tres componentes del SSIS:
- Flat File Source: Fuente de datos, se conecta con el FCCM_ArchivoDummy.
- Derived Column: Herramienta útil para la conversión de datos. Mas adelante vamos a detallar su uso.
- Ole DB Destination: Conexión con Sql Server, con la tabla DummyCargaSSIS. Donde vamos a guardar los datos.
Derived Column
Estas en una de la grandes virtudes que tiene Sql Server Integration Service, el poder validar, castear, modificar el valor, etc de los campos que vamos a procesar. Vamos a detallar su uso y como podemos desde este componente convertir juegos de caracteres de UTF8 a ANSI 1252 o leer un determinado formato de fecha y pasarlo según el formato que lo requiere el destino.
Se puede observar que vamos a derivar 4 campos: Código, fecha creación, nombre, y fecha de baja. Comencemos con el primero:
Analicemos el campo "Codigo"
En la configuración de Flat Flat Connection, recuerde que dejamos el "Code Page" con el valor 65001 (UTF-8). Necesito convertirlo a ANSI 1252, ya que nuestra BD asi esta. Entonces lo que procede es escribir en "Expression":
(DT_STR,10,1252)SUBSTRING(Codigo,1,10)
Hemos resaltado dos colores en esta expresión. Vamos con la primera
- (DT_STR,10,1252): Estamos indicando que vamos a castear el campo codigo, que es de tipo String, con longitud 10, y que se pasa del UFT-8 al ANSI 1252. Con esto solventamos el problema de guardar los caracteres especial en la base de datos.
- SUBSTRING(Codigo,1,10): Con esto solo estamos indicando que vamos a tomar el campo código los caracteres del 1, con longitud 10. Tal vez no es necesario esto, pero estoy validando que solo tome los primeros 10 caracteres.
- Como se puede observar en el dibujo, a la columna derivada le estamos indicando que se va a llamar CodigoOut.
Analicemos el campo "FechaCreacion"
- Si recuerdan, este dato viene en la segunda posicion del archivo, para la primera fila trae "25/05/2017". Este es un formato DD/MM/YYYY, ok entonces procedamos a tratar este datos y lo convertimos al formato de Sql Server.
LEN(TRIM(SUBSTRING(FechaCreacion,1,10))) == 10 ? (DT_DBDATE)(SUBSTRING(FechaCreacion,7,4) + "-" + SUBSTRING(FechaCreacion,4,2) + "-" + SUBSTRING(FechaCreacion,1,2)) :NULL(DT_DBDATE)
- Evaluamos la expresion, si tiene los 10 caracteres.
- En la evaluacion (a==b?true:false), en la parte true (?), realizamos un casteo de tipo DT_DBDATE y armamos las fecha en formato YYYY-MM-DD,
- Si el campo viene null entonces en la parte false (:), mandamos como resultado (DT_DBDATE)NULL
- Nombre derivado: FechaCreacionOut
El formato de la fecha puede venir DDMMYYY, YYYYMMDD, etc, lo que debemos hacer es leer la posición que representa cada dato y formatearlo al estilo de Sql Server (YYYY-MM-DD) u otro estilo que se requiera.
Analicemos el campo "Nombre"
El tratamiento a esto campo es muy similar al campo "Codigo", con la diferencia que omitimos la instrucción SUBSTRING. Nombre derivado: NombreOut.
Analicemos el campo "FechaBaja_Out"
Volvamos al archivo de texto, el valor para este campo viene en la ultima columna, vemos que la fecha viene con formato DD/MM/YYYY y por cierto a veces viene vacio. Aqui vamos a tomar otro camino, en vez de manipular la cadena String, vamos a proceder a utilizar el cast de fecha de SSIS.
LEN(TRIM(FechaBaja)) == 10 ? (DT_DATE)FechaBaja : NULL(DT_DATE)
- Primero valida si cumple con la longitud del formato que es 10.
- Si cumple, entonces realiza el casteo (DT_DATE)FechaBaja. En este punto SSIS es capaz de reconocer en el formato que viene la fecha y la convierte implicitamente al formato de Sql Server.
Si me pregunta que camino tomo, prefiero irme siempre por la manipulación de string y formatear la fecha. Y creo que el rendimiento es mucho mejor.
Al ejecutar el SSIS entonces tenemos el resultado esperado
Espero les sirva 👊